Why CACTOS?
User demand and new technologies are driving a drastic increase in cloud infrastructure scale, heterogeneity and complexity. The demand for better energy efficiency has led to a variety of technological options to build servers from different CPU architectures as well as specialised options for highly parallel tasks such as manycore systems or General Purposed GPUs. At the same time, service provisioning has evolved from Web Services and infrastructure virtualisation to Clouds, which is conceptually very similar to the evolution from traditional server hosting to more interactive services (e.g. remote rendering or gaming).
CACTOS delivers three major results. CactoScale: A set of tools and methods to acquire and analyse application behaviour and infrastructure performance data. CactoOpt: Mathematical models and their realisation to determine the best fitting resources within a provider context. CactoSim: A prediction and simulation environment for diverse application workloads
Modern offerings go beyond simple services, including full platforms, complex compositions and whole infrastructures. This leads to a significant complexity in mapping the different modules of these solutions on the large variety of available hardware options. Similarly data centres have made significant investments in energy efficient buildings, server racks and facility management technology and understand themselves as Smart Consumers in evolving SmartGrid environments.
To cope with the challenge to optimise the mapping of services to a variety of different resources, both hardware and software related (e.g. high bandwidth demands), requires topology aware mapping. This mapping needs to consider placement of the services across geographically distributed centres and demands new intelligent and cross-domain integration of actual and historical usage data.
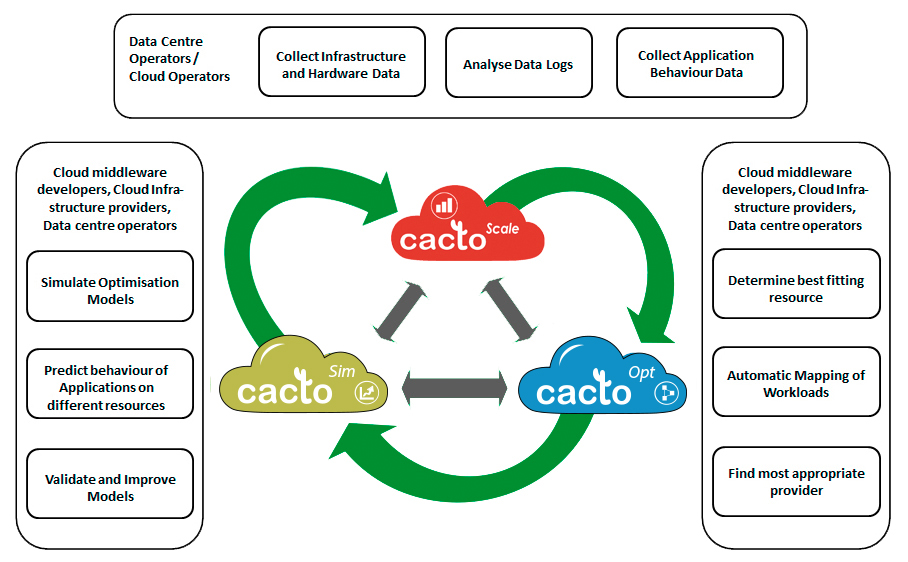
The CACTOS Vision
Realizing the CACTOS vision means that the variety of workloads supposed to be executed in a Cloud environment can be mapped automatically to the most appropriate resources in the best fitting data centre at a given time and that in case of failures or changing conditions the best matching place is automatically detected and the workload is relocated.
The underpinning idea is based on the assumption that cloud applications can be described and analysed in terms of workload behaviour, potentially split into segments representing different classes of workload and that an optimised placement of the application elements is feasible relying on rich resource descriptions providing the necessary information from server node capabilities over cluster and data centre topology up to environmental data collected by sensors from the facility management system and business data such as actual power costs.
In order to realize this vision, in addition to the existing traces available at the start of the project the consortium will collect further data on the actual use of cloud infrastructures. In parallel, a workload model, based on an analysis of applications as well as on synthetic workloads (with defined behaviour), and an infrastructure model, based on different hardware architecture, further extend the information basis. The top-down and bottom-up models are developed initially in parallel and later integrated into a holistic optimization model. These individual models are validated in the first project cycle using a simulator. Over the project time the models are integrated in several iterations and validated within the selected Cloud Middleware on a physical infrastructure as well as using simulation in order to extend the validation beyond the typical limits in size of prototypical infrastructure.